Visuelles Tracing bietet Einblicke in RTOS-Firmware
Dr. Johan Kraft, CEO und Firmengründer, Percepio AB
Das Debugging RTOS-basierter Systeme lässt sich durch verbesserte Einblicke in deren Echtzeit-Ausführung drastisch vereinfachen. Damit einhergehend profitiert man von einer Verkürzung der Debugging-Zeit von Tagen oder gar Wochen auf nur mehr Stunden. Voraussetzung hierfür ist ein Software-Tracing auf RTOS-Ebene, und hierbei kommt es auf eine gute Visualisierung an, damit man die erzeugten Daten sinnvoll interpretieren kann.
Ein Echtzeit-Betriebssystem (engl. Real-Time Operating System, RTOS) ist ein schnelles,deterministisches Betriebssystem, das klein genug für die Verwendung in Mikrocontrollern (MCUs) ist. RTOSs eignen sich daher ideal für Embedded- und IoT-Anwendungen. Dass Entwickler zunehmend RTOSs verwenden, liegt daran, dass diese bei der Verringerung der Codekomplexität helfen, feste Timing-Deadlines garantieren und die Wiederverwendung von Softwaremodulen erleichtern. Die durch die Nutzung eines RTOS auferlegte Struktur verbessert die Pflegbarkeit einer Applikation und vereinfacht das Hinzufügen neuer Features. Für das Management ist all dies von Vorteil, weil es die
Entwicklungs-Effizienz steigern, die Markteinführungszeit verkürzen und sowohl die Produktzuverlässigkeit als auch die Kundenzufriedenheit verbessern kann.
Allerdings werden diese Vorzüge mit einigen Komplexitäten erkauft. Subtile Entscheidungen bei der Codierung können zu diffizilen, im Quellcode nicht erkennbaren Fehlern oder Performance-Problemen im finalen Produkt führen. Während das System im Labor wie vorgesehen zu funktionieren scheint, gibt es doch unzählige Szenarien, die sich durch Testen oder Code-Reviews unmöglich alle abdecken lassen. Im ungünstigsten Fall besteht das System sämtliche Tests, nur um dann beim Kunden abzustürzen. Damit ein zuverlässiger Betrieb gewährleistet ist, müssen beim Applikations-Code die
bewährte Methoden für das RTOS-basierte Design befolgt werden, was allerdings gute Einblicke in das Echtzeit-Verhalten des Systems voraussetzt.
Man kann sich die Trace-Visualisierung wie eine Zeitlupenaufnahme der internen Abläufe in der Applikation vorstellen.
Kommt es zu solchen Problemen, kann das Debugging zu einem Alptraum werden, denn die Umstände, die zu dem Problem geführt haben, sind häufig nicht im Detail bekannt und lassen sich dementsprechend nur schwierig reproduzieren. Die Entwickler stochern hier oft im Nebel und müssen eine Möglichkeit nach der anderen ausprobieren, um die Applikation ordnungsgemäß zum Laufen zu bringen. Um aber sicher sein zu können, dass das Problem tatsächlich behoben ist, muss man über die genaue Abfolge der Software-Ereignisse Bescheid wissen, die zu dem Problem geführt haben – einschließlich der Interaktionen zwischen Applikation und RTOS. Traditionellen Debugging-Werkzeugen fehlt diese Fähigkeit allerdings.
Die RTOS-Trace-Visualisierung, die man sich wie eine Zeitlupenaufnahme der internen Abläufe der Applikation vorstellen kann, ist eine gute Möglichkeit die Gewissheit darüber zu verschaffen, dass eine RTOS-Software wie beabsichtigt funktioniert. Außerdem ist sie die schnellste Möglichkeit zum Erkennen und Beseitigen von Fehlern.
Herausforderungen beim RTOS-basierten Design
Die Hauptaufgabe eines RTOS ist es, das Multitasking zu ermöglichen, was eine Aufteilung der Funktionalität einer Software in mehrere „parallele“ Programme, sogenannte Tasks, gestattet. Ein RTOS schafft also die Illusion des Parallelbetriebs, indem die Verarbeitung schnell von einer Task zur anderen wechselt. Im Unterschied zu Universal-Betriebssystemen gibt ein RTOS dem Entwickler die vollständige Kontrolle über das Multitasking und ermöglicht damit ein deterministisches Echtzeitverhalten.
Ein RTOS übernimmt die Kontrolle über die Programmausführung und führt einen neuen Abstraktionsgrad in die Form dieser Tasks ein. Wird ein RTOS verwendet, geht der Kontrollfluss eines Programms nicht mehr aus seinem Quellcode hervor, denn das RTOS entscheidet, welche Task zum jeweiligen Zeitpunkt ausgeführt wird. Dies stellt ähnlich wie der Umstieg von Assembler- auf CProgrammierung eine grundlegende Umstellung dar, die dank des höheren Abstraktionsgrads einen Produktivitätsgewinn möglich macht, gleichzeitig aber auch bedeutet, dass weniger Kontrolle über einzelne Details besteht.
Ein RTOS kann zwar die Komplexität des Quellcodes der Applikation reduzieren, verringert aber nicht
die der Applikation innewohnende Komplexität.
Wir haben es hier also mit einem zweischneidigen Schwert zu tun: Das Design komplexer Applikationen mag einfacher werden, aber das Validieren und Debuggen dieser Applikationen kann sich hinterher schwieriger gestalten. Ein RTOS kann zwar die Komplexität des Quellcodes der Applikation reduzieren, verringert aber nicht die Komplexität, die der Applikation selbst innewohnt. Eine Reihe scheinbar einfacher RTOS-Tasks kann, wenn sie als System ausgeführt werden, zu einem überraschend komplexen Echtzeitverhalten führen.
Die Entwickler müssen vorgeben, wie die Tasks mithilfe der RTOS-Dienste interagieren und Daten untereinander austauschen sollen. Überdies müssen Entwickler über wichtige RTOS-Parameter wie etwa die Priorität (d. h. die relative Dringlichkeit) der Tasks entscheiden, die alles andere als selbstverständlich sein kann. Selbst wenn der gesamte Code nach den bewährten Methoden für RTOSbasiertes Design geschrieben wurde, kann es sein, dass andere Systembestandteile – ob aus eigener Entwicklung oder zugekauft – in derselben RTOS-Umgebung laufen, sich aber nicht an dieselben Prinzipien halten.
Das grundlegende Problem, welches das RTOS-basierte Design so schwierig macht, ist die Tatsache, dass es sich bei RTOS-Tasks nicht um isolierte Objekte handelt, denn es bestehen Abhängigkeiten, die die Ausführung einer Task auf unvorhergesehene Weise verzögern oder anhalten können. Dieskann die Leistungsfähigkeit beeinträchtigen, das System dazu bringen, dass es nicht reagiert oder instabil wird, oder sogar zu intermittierenden Datenverlusten führen.
Zwischen den Tasks besteht mindestens die eine Abhängigkeit, dass sie die Verarbeitungszeit desselben Prozessors nutzen. Tasks mit höherer Priorität können aktiv werden und die Prozessorzeit zu nahezu jedem Zeitpunkt für sich beanspruchen, bis alle aktiven höher prioren Tasks abgearbeitet sind.
Hinzu kommt, dass Tasks häufig bestimmte Software-Ressourcen gemeinsam nutzen (z. B. globale Daten oder Schnittstellentreiber). Dies erfordert blockierende Synchronisations-Aufrufe, um Zugriffskonflikte auszuschließen. Derartige Task-Abhängigkeiten können von vielen Faktoren beeinflusst werden, zu denen Änderungen bei den Eingangswerten, dem Timing der Eingangswerte oder der Task-Verarbeitungszeiten zählen.
Solche Probleme sind im Code nicht erkennbar und lassen sich oft auch mit Modultests nicht aufdecken, treten aber im integrierten Produkt dennoch auf – entweder beim Test des Gesamtsystems oder auch erst beim Kunden. Dies macht es schwierig, diese Phänomene für Debugging-Zwecke zu reproduzieren, solange nicht die genaue Sequenz der Software-Ereignisse bekannt ist, die dem Problem vorausgingen.
Aufdecken von Fehlern in RTOS-basierten Systemen
Als die Embedded-Branche von Assembler- auf C-Programmierung umstellte, zog man bei den Debugging-Tools schnell nach und bot das Quellcode-Debugging an, wodurch die C-Code-Perspektive zur normalen Debugging-Ansicht wurde. Leider haben sich die Tools in der Regel nicht über dieses Level hinaus weiterentwickelt. Einige wurden durch Features ergänzt, mit denen Entwickler den Zustand von RTOS-Objekten wie Tasks oder Semaphoren untersuchen können. Dies reicht aber nicht aus. Ein RTOS-Debugging-Tool muss vielmehr das Konzept „Zeit“ verstehen, damit es Ereignisse korrelieren kann. Außerdem muss es den Entwicklern die Möglichkeit geben, das Echtzeit-Verhalten
einer Applikation zu beobachten.
Dies verlangt nach RTOS-Tracing, was bedeutet, dass die Software-Ereignisse im Laufzeit-Code, im RTOS-Kernel und optional auch im Applikations-Code für die hostseitige Analyse aufgezeichnet werden.
Eine gute Visualisierung ist entscheidend zum Verstehen von RTOS-Traces. Viele Embedded-Systeme legen zudem ein zyklisches Verhalten an den Tag, sodass ein Trace großenteils aus Wiederholungen des normalen Ablaufmusters besteht. Interessant sind meist die Anomalien, die jedoch in einem Rohdatenstrom möglicherweise nur schwierig zu erkennen sind. Bei einer grafischen Darstellung dagegen treten die Anomalien klar hervor.
Ein RTOS-Debugging-Tool muss das Konzept „Zeit“ verstehen, Ereignisse korrelieren können und Entwicklern die Möglichkeit geben, das Echtzeit-Verhalten einer Applikation zu beobachten.
Ein Debugging-Tool, das die Ereignisse und Datenstrukturen eines RTOS versteht, kann aus einem Trace außerdem weit mehr Informationen extrahieren als nur den grundlegenden Verarbeitungsablauf. Zum Beispiel besteht die Möglichkeit zum Erstellen eines Abhängigkeitsdiagramms, aus dem die Interaktionen zwischen Tasks, Interrupt Service Routinen und RTOS-Objekten wie etwa Semaphoren und Message Queues hervorgehen.
Sehen heißt verstehen
Die primäre Aufgabe eines Software-Tracing-Tools besteht im Erfassen von Ereignissen im Zielsystem.
Die Skala reicht hier von Scheduling- und RTOS-Aufrufen bis zu Timer-Ticks und applikationsspezifischen Log Messages. Man braucht jedoch nur einen kurzen Blick auf ein typisches Event Log (siehe Abbildung unten) werfen, um zu erkennen, dass dieses zwar sinnvoll sein mag, dass sich ein solches Textdokument aber nicht auf die großen Datenmengen skalieren lässt, die beim Software-Tracing entstehen. Das gezeigte Beispiel bezieht sich auf eine Ausführungszeit von nur etwa 2ms. Ein RTOS-Trace, das sich über mehrere Minuten erstreckt, kann dagegen Millionen von Ereignissen enthalten.
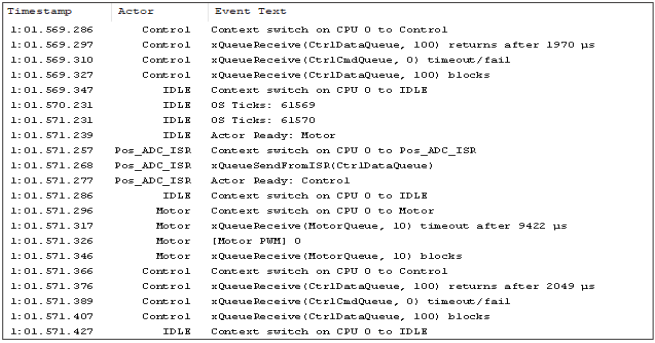
Ein Event Log kann zwar informativ sein, lässt sich jedoch nicht auf einen großen Umfang an Trace-
Daten skalieren
Das Auffinden eines Fehlers in einem umfangreichen Text-Log gleicht der sprichwörtlichen Suche nach der Stecknadel im Heuhaufen – und man weiß dabei nicht einmal, wie die Nadel aussieht, wonach man also eigentlich sucht. Um die nächste Ebene zu erreichen, also zu verstehen, welches Verhalten beabsichtigt ist und welches nicht, sind Entwickler auf geeignete Tools zum Visualisieren der Daten angewiesen.
Das Auffinden eines Fehlers in einem umfangreichen Text-Log ist wie die Suche nach der Stecknadel im
Heuhaufen, ohne zu wissen, wie die Nadel aussieht.
Besser lassen sich große Mengen an RTOS-Trace-Daten mit einer grafischen Trace-Ansicht in der Art eines Gantt-Diagramms (Balkenplan) darstellen. Die Trace-Daten erscheinen dabei entlang einer interaktiven Zeitleiste. Entwickler können somit in einer niedrigen Zoomstufe den Überblick über umfangreiche Trace-Daten gewinnen und abnormale Muster identifizieren, um anschließend den Zoomfaktor zu erhöhen, damit Einzelheiten sichtbar werden. Eine grafische Trace-Darstellung muss sich nicht auf die Ausführung der RTOS-Tasks beschränken, sondern kann auch API-Aufrufe, Log Messages der Applikation und andere Ereignisse einschließen, wie das folgende Beispiel zeigt.

Die Trace-Ansicht in Percepio Tracealyzer zeigt die Trace-Daten entlang einer vertikalen Zeitleiste.
Ein Problem, mit dem die Entwickler von Embedded-Systemen häufig zu tun haben, ist die Tatsache, dass die Zielsysteme häufig in ihrer CPU-Leistung und ihrem Speicherplatz beschränkt sind. Hier kann ein CPU-Auslastungsdiagramm, wie es nachfolgend gezeigt ist, hilfreich sein. Es gibt an, wieviel Prozessorzeit die einzelnen Tasks und Interrupt-Serviceroutinen beanspruchen. Anhand dieser Informationen lässt sich schnell erkennen, an welchen Stellen die Auslastung über eine längere Zeitspanne nah an 100 % liegt (was wahrscheinlich zu einer verzögerten Ausführung von Tasks führt), und wieviel CPU-Zeit für neue Features verfügbar ist, ohne dass die Hardware aufgerüstet werden muss.
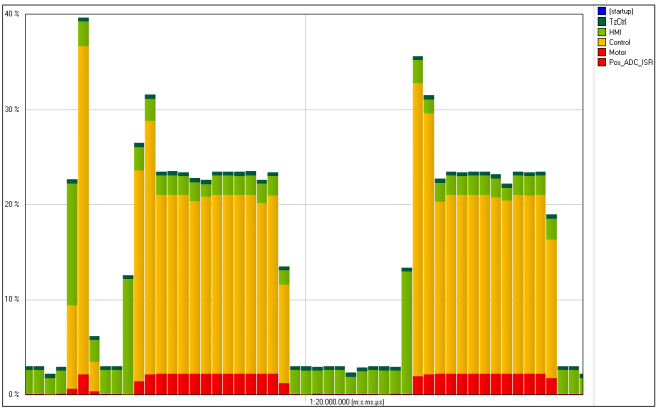
Ein CPU-Auslastungsdiagramm aus Percepio Tracealyzer veranschaulicht, wieviel Prozessorzeit die einzelnen Tasks im Lauf der Zeit beanspruchen. Dies zeigt klar, wenn eine bestimmte Task deutlich mehr CPU-Ressourcen verbraucht als andere.
Um auf den Debugging-Aspekt des Tracings zurückzukommen, wird eine durchgegangene Task, die mehr CPU-Zeit als vorgesehen beansprucht, in einem CPU-Auslastungsdiagramm deutlich auszumachen sein. Gleiches gilt für Tasks, die das ineffiziente „Busy Waiting“ nutzen. Dies nämlich vergeudet CPU-Zeit, die sonst für andere Tasks verfügbar wäre, und ist ein häufig begangener Verstoß gegen die Regeln für gutes RTOS-basiertes Design.
Durch das Verfolgen von API-Aufrufen erfasst man tatsächlich Abhängigkeiten zwischen den Tasks, und diese kann ein Tool in einem Abhängigkeitsdiagramm visualisieren, wie es unten zu sehen ist. Eine solche visuelle Zusammenfassung des Applikationsdesigns liefert die Gewissheit, dass der Applikations-Code wie vorgesehen funktioniert. Außerdem kann sie Bugs aufdecken, die mit falschen oder fehlenden API-Aufrufen zusammenhängen und somit zu Stabilitätsproblemen führen können.
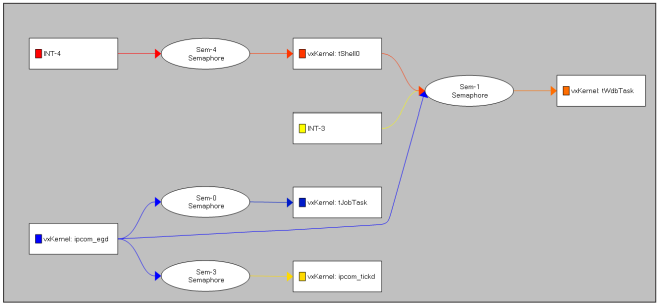
Dieses Kommunikationsfluss- oder Abhängigkeitsdiagramm ist ein geeigneter Ausgangspunkt für viele Debugging-Sitzungen, denn es bietet gleichsam aus der Vogelperspektive einen Blick auf die Architektur der Applikation, woraufhin Entwickler jedes Objekt im Diagramm mit einem Doppelklick genauer unter die Lupe nehmen können.
Ein gutes Tracing-Tool sollte Entwicklern außerdem die Möglichkeit zum Aufzeichnen individueller, applikationsspezifischer Daten im Rahmen des Trace-Streams geben. Die betreffenden Ereignisse können für beliebige Zwecke verwendet werden; eine gängige Nutzung ist aber das Aufzeichnen wichtiger Variablenwerte und Zustandsänderungen aus dem Applikations-Code.
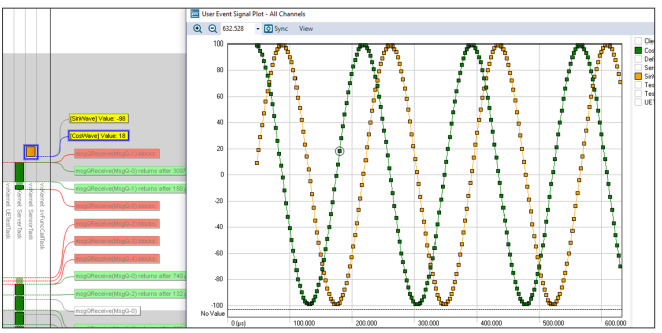
Percepio Tracealyzer macht es möglich, Applikationsdaten aufzuzeichnen und über die Zeit grafisch darzustellen.
Ein Beispiel aus der Praxis: Prioritätsinversion auf dem Mars
Ein höchst prominentes und kostspieliges Beispiel für diese Art von Problemen trat während der Pathfinder-Mission der NASA auf, bei der 1997 ein Rover auf dem Mars gelandet wurde. Während der Mission kam es im Raumfahrzeug zu kompletten System-Resets, die Datenverluste zur Folge hatten.
Nach erheblichen Problemen fand die NASA heraus, dass die Ursache in einem klassischen RTOS Problem lag, das als Prioritätsinversion bekannt ist.
Zu einer Prioritätsinversion kann es kommen, wenn eine Task hoher Priorität (die rot dargestellte Task H in der folgenden Abbildung) auf eine geteilte Ressource wie etwa eine Kommunikationsschnittstelle zugreifen will, die gerade von einer Task mit geringerer Priorität (Task L, grün) genutzt wird. Task H würde normalerweise für eine kurze Zeitspanne blockiert, bis Task L die geteilte Ressource freigibt. Zu einer Prioritätsinversion kommt es, wenn an dieser Stelle eine Task mittlerer Priorität (Task M, gelb) Task L unterbricht und die hoch priore Task dadurch verzögert, wie unten dargestellt. Bei der Pathfinder-Mission der NASA führte dies zu wiederholten Timeout-Fehlern mit daraus resultierenden Resets, Datenverlusten und beinahe auch zu einem Fehlschlag der Mission.
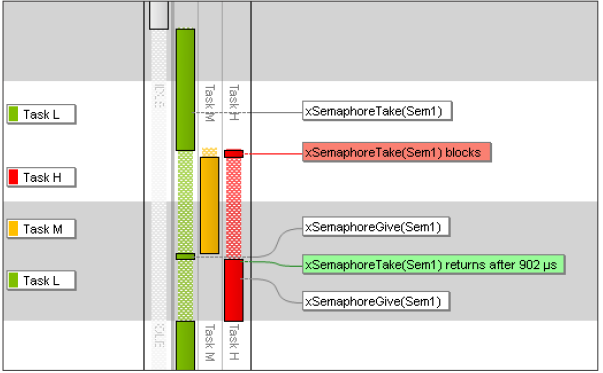
Prioritätsinversion, dargestellt in Percepio Tracealyzer.
Durch Tracing können Entwickler Probleme dieser Art detektieren und vermeiden. Das Tracing umfasst das Aufzeichnen des Softwareverhaltens zur Laufzeit, damit die gesammelten Trace-Daten im Nachgang analysiert werden können. Das Tracing erfolgt oftmals im Entwicklungslabor, kann aber auch in der Produktion genutzt werden, wo es ununterbrochen aktiv ist, um das Verhalten aufzuzeichnen und Fehler nach dem Deployment aufzudecken. Das Produktions-Tracing kann eine effektive Technik zum Detektieren selten auftretender Fehler sein, die sich in einem Debugger nur schwierig reproduzieren lassen. Unter anderem kann es um Fälle gehen, in denen ein System langsamer reagiert als erwartet, falsche oder suboptimale Ergebnisse ausgibt, stehen bleibt oder abstürzt.
Hardware- oder Software-Tracing?
Das Tracing kann entweder in der Hardware (im Prozessor) oder in der Software erfolgen. Das hardwarebasierte Tracing erzeugt eine detaillierte Verarbeitungs-Historie auf der Befehlsebene, während sich das softwarebasierte Tracing auf ausgewählte Software-Ereignisse konzentriert – meist im Betriebssystem und in wichtigen Schnittstellen auf der Applikations-Ebene. Ein per Hardware generierter Trace liefert Einzelheiten zum Kontrollfluss, beeinflusst nicht die Verarbeitung des untersuchten Systems, setzt aber spezielles Equipment und eine tracefähige Hardwareplattform
voraus.
Das softwaregenerierte Tracing erfordert keine besondere Hardware und kann – ähnlich wie ein Flugschreiber in der Luftfahrt – auch in bereits ausgelieferten Produkten installiert werden. Das Software-Tracing ermöglicht außerdem das Abspeichern beliebiger Applikationsdaten bei den besagten Ereignissen, darunter lokale Variablen und Funktionsparameter, während das Hardware-Tracing oftmals auf den Kontrollfluss sowie möglicherweise globale Datenzugriffe beschränkt ist, wenn man einen durchsatzstarken Trace-Port voraussetzt. Das Software-Tracing bringt eine gewisse Mehrbelastung der CPU mit sich, die jedoch normalerweise kaum spürbar ist (nur wenige Prozent).
Das Software-Tracing benötigt RAM im Zielsystem zum temporären Zwischenspeichern der Trace-Daten. Die RAM-Puffer sind jedoch meist konfigurierbar, um RAM-Bedarf und Puffergröße in Einklang zu bringen.
Besonders wichtig ist das Tracing für Systeme mit integriertem RTOS. Ein zentrales Merkmal von RTOSs ist das Multitasking, also die Fähigkeit zur Verarbeitung mehrerer Programme (Tasks) auf einem einzigen Prozessorkern, indem schnell zwischen den verschiedenen Anwendungskontexten gewechselt wird. Das Verhalten der Software allerdings wird durch das Multitasking komplexer, und die Entwickler haben weniger Kontrolle über das Laufzeitverhalten, da die Ausführung vom RTOS unterbrochen wird.
Hardware-Tracing
- Generiert durch Features der CPU
- Exakte Befehlssequenz
- Nicht-invasiv
- Oft wird nur der Kontrollfluss erfasst
- Allgemeines Daten-Tracing ist wegen der hohen Datenraten auf spezielle Chips und Boards angewiesen
- Nur für den Laboreinsatz
- Beispiele:
- Lauterbach Trace-32
- iSystem Bluebox
Software-Tracing
- Per Software generiert
- Höherer Abstraktionsgrad
- RTOS-Taskausführung
- API-Aufrufe
- Applikationsspezifische Aufzeichnung
- Nutzt CPU und RAM des Zielsystems
- Beliebige Software-Ereignisse und Daten
- Möglichkeit tiefergehender Analysen
- Keine zusätzliche Hardware erforderlich
- Für den Laboreinsatz
- Als Absturzrekorder auch für die Verwendung im Feld
- Beispiele:
- Wind River System Viewer
- Percepio Tracealyzer
“Die vielen Systemansichten von Percepio Tracealyzer erleichtern das schnelle Ermitteln von Lösungen, die wir mit System Viewer nicht gesehen haben. Die Visualisierung hat zahlreiche Vorteile gegenüber System Viewer und macht es einfacher, das Systemverhalten zu verstehen.” Johan Fredriksson, Software Architect, SAAB AB
Schluss mit dem Rätselraten
Das Debugging RTOS-basierter Systeme lässt sich drastisch vereinfachen, verbunden mit einer Reduzierung der Debugging-Zeit von Tagen oder Wochen auf nur mehr Stunden sowie besseren Einblickmöglichkeiten in deren Echtzeit-Verarbeitung. Nötig ist hierfür ein Software-Tracing auf der RTOS-Ebene, und hier ist eine gute Visualisierung entscheidend dafür, dass verwertbare Informationen aus den Daten extrahiert werden können. Zwar gibt es durchaus mehrere Tools, die ein einfaches RTOS-Tracing bieten, aber erst mit einer ausgefeilten Visualisierung wird es deutlich einfacher, den Trace zu verstehen, wichtige Probleme zu identifizieren und die Lösungen zu verifizieren.

 damit Probleme schneller, vermeiden diese und optimieren die Performance Ihres Systems schnell und einfach.
damit Probleme schneller, vermeiden diese und optimieren die Performance Ihres Systems schnell und einfach.